分布式系统之二:数据分布
在分布式系统中,数据需要根据一定策略存储在不同的节点。一方面是保证数据冗余,避免单点故障;另一方面是提高扩展性,通过横向扩展数据节点,提高系统性能。
目前主流的方案主要有:
- master-slave方案
从节点作为主节点的备份,能实现数据冗余,但是不利于扩展;常见的应用就是读写分离,达到备份的效果同时一定程度上提升了性能。
但是比较难做到强一致性,所以从库不建议面向用户,可以用来做计算处理类的业务。
- master-master方案
多个master节点,都负责读写业务,通常为了实现数据冗余,每个节点的数据会在其他节点备份。
当然实际应用中,有各种各样的基于上述两个的柔和、变种。
例如GP的双master+node方案,两个master满足master-slave架构,但是master只负责计算和元数据,node之间是master-master架构;
Kafka则做到了partition的级别,每个partition都有自己的master和slave。
无论哪种分布方案,如果需要可扩展,都需要多节点读写的MM架构,也就需要实现数据分片。常见的数据分片方案如下。
哈希分布
哈希分布就是将数据计算哈希值之后,按照哈希值分配到不同的节点上。例如有 N 个节点,数据的主键为 key,则将该数据分配的节点序号为:hash(key)%N。
传统的哈希分布算法存在一个问题:当节点数量变化时,也就是 N 值变化,那么几乎所有的数据都需要重新分布,将导致大量的数据迁移。
顺序分布
将数据划分为多个连续的部分,按数据的 ID 或者时间分布到不同节点上。例如 User 表的 ID 范围为 1 ~ 7000,使用顺序分布可以将其划分成多个子表,对应的主键范围为 1 ~ 1000,1001 ~ 2000,…,6001 ~ 7000。
顺序分布相比于哈希分布的主要优点如下:
- 能保持数据原有的顺序;
- 并且能够准确控制每台服务器存储的数据量,从而使得存储空间的利用率最大。
一致性哈希
Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了克服传统哈希分布在服务器节点数量变化时大量数据迁移的问题。
基本原理
将哈希空间 [0, 2n-1] 看成一个哈希环,每个服务器节点都配置到哈希环上。每个数据对象通过哈希取模得到哈希值之后,存放到哈希环中顺时针方向第一个大于等于该哈希值的节点上。
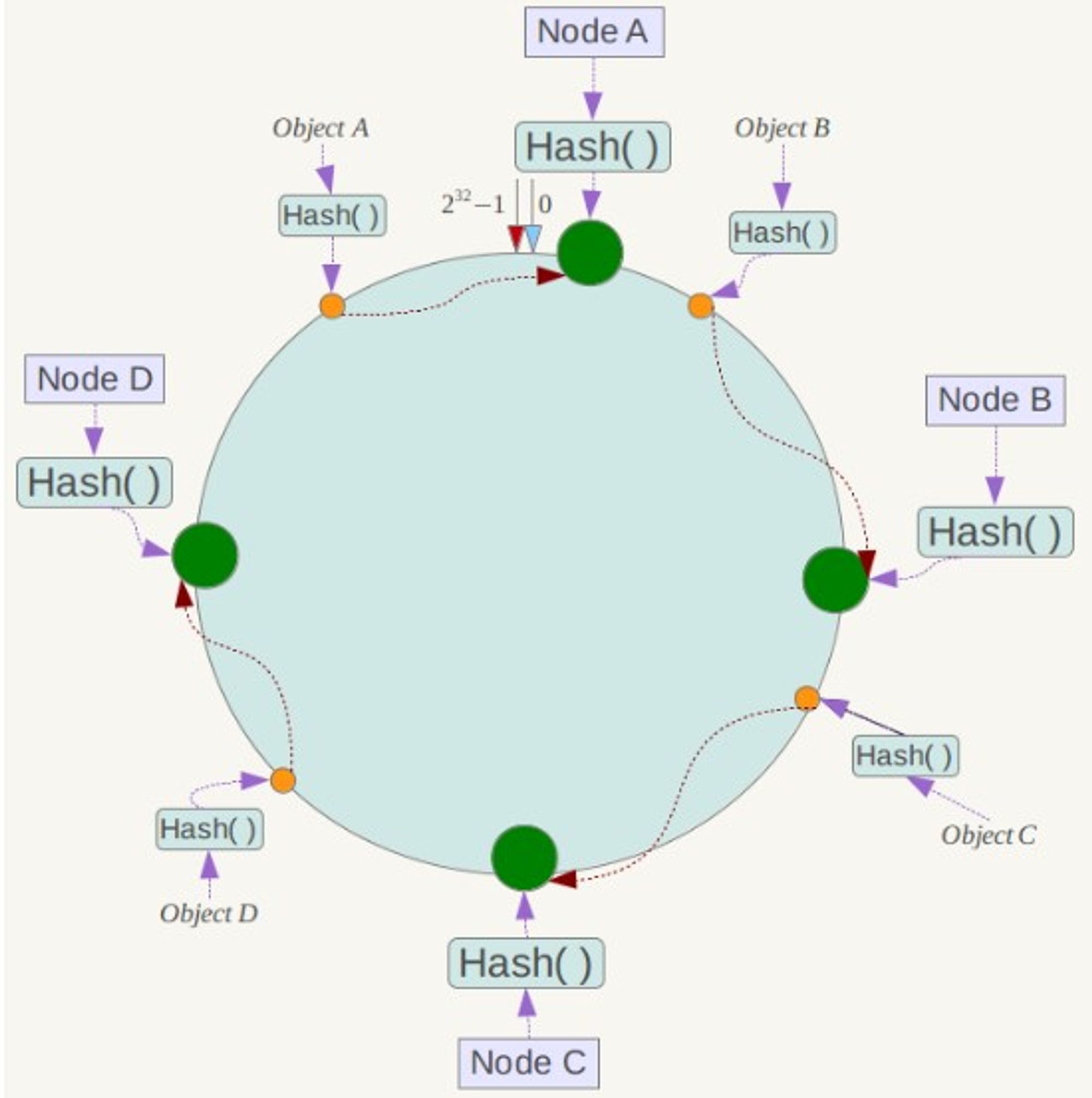
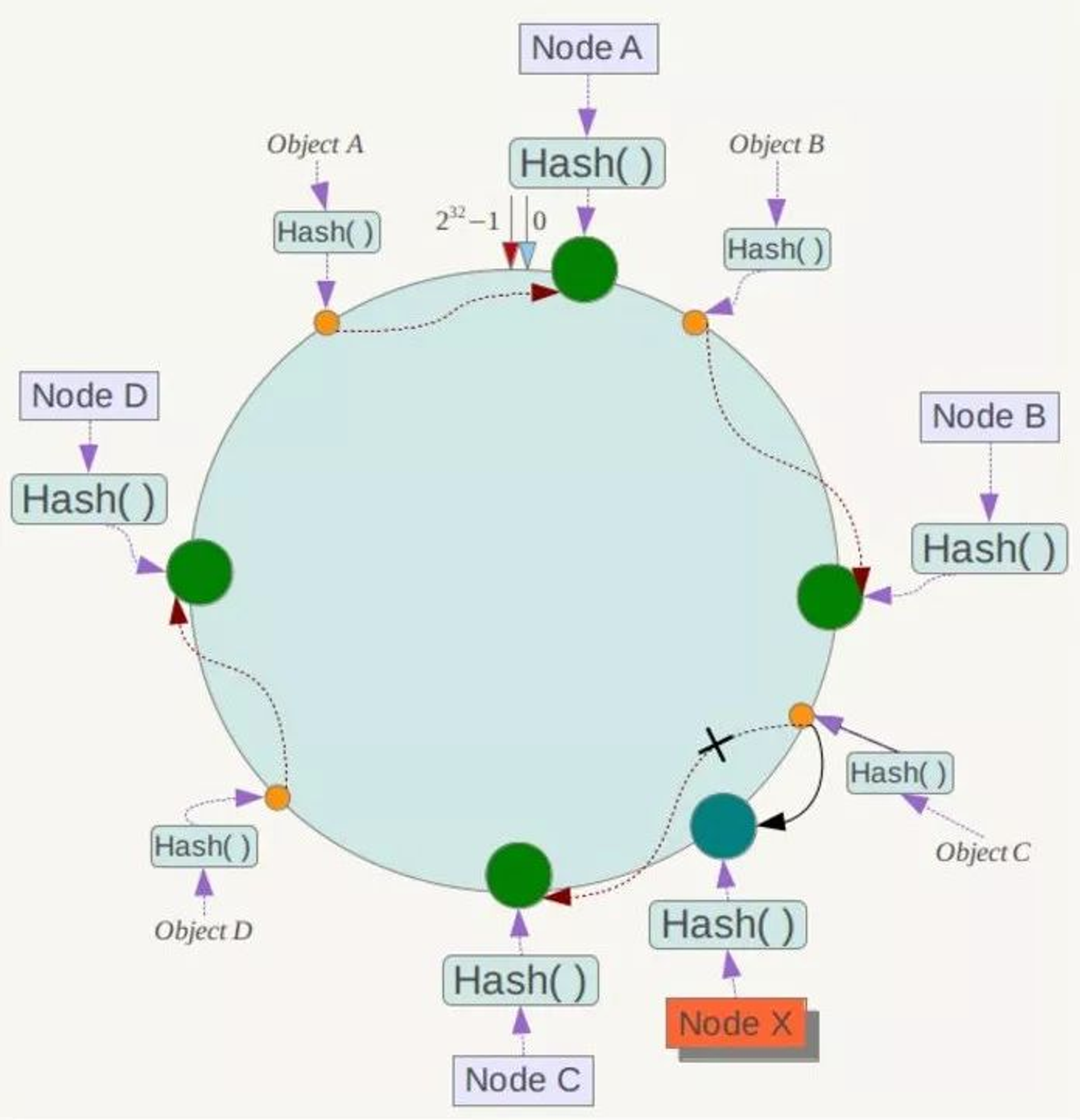
一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它前一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响。
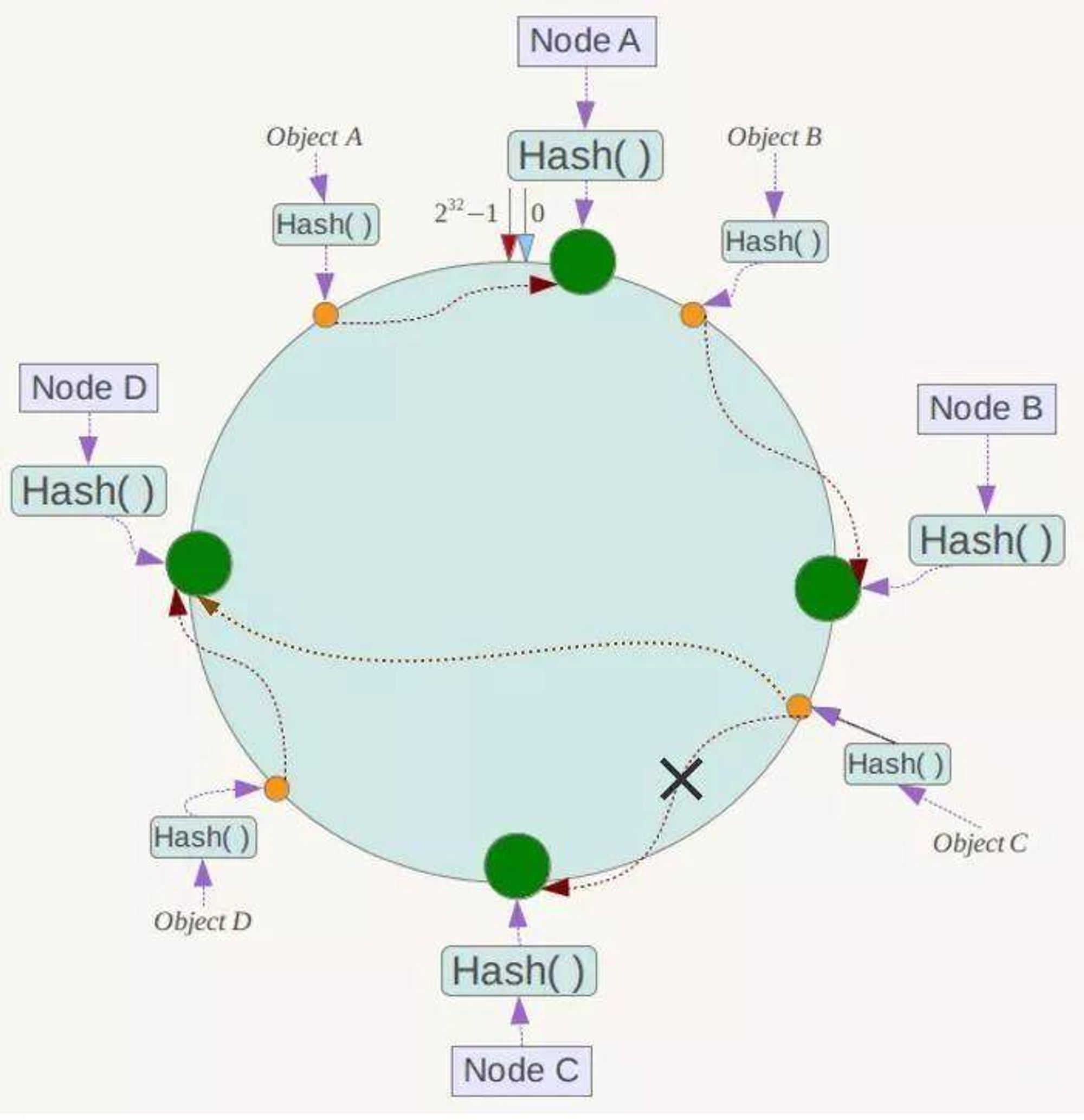
假设 Node C 节点挂掉了,Object C 的存储丢失,那么它顺时针找到的最新节点是 Node D。也就是说 Node C 挂掉了,受影响仅仅包括 Node B 到 Node C 区间的数据,并且这些数据会转移到 Node D 进行存储。
虚拟节点
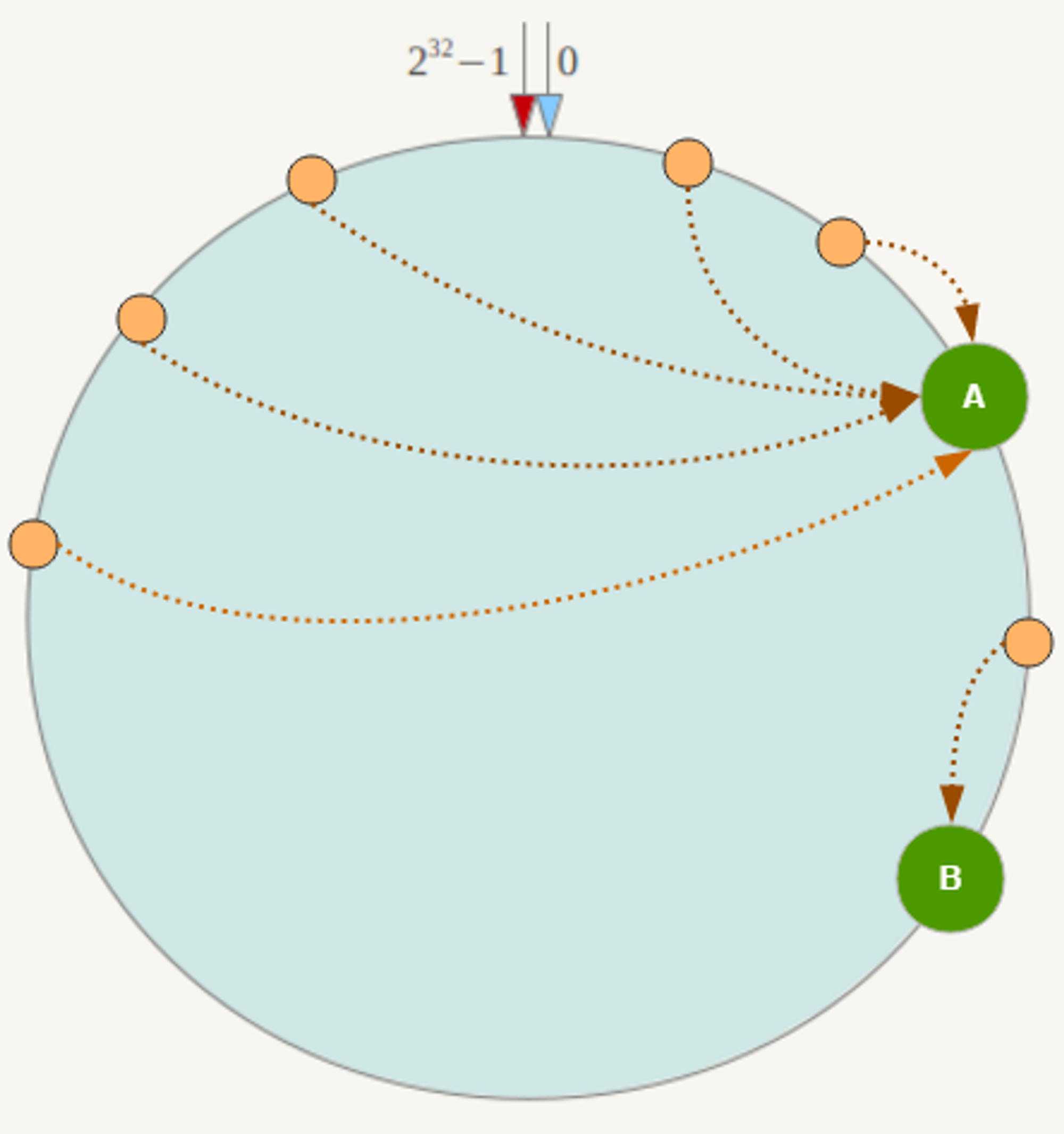
所以一致性哈希算法对于容错性和扩展性有非常好的支持。但一致性哈希算法也有一个严重的问题,就是数据倾斜。
如果在分片的集群中,节点太少,并且分布不均,一致性哈希算法就会出现部分节点数据太多,部分节点数据太少。也就是说无法控制节点存储数据的分配。如下图,大部分数据都在 A 上了,B 的数据比较少。
解决方式是通过增加虚拟节点,然后将虚拟节点映射到真实节点上。虚拟节点的数量比真实节点来得多,那么虚拟节点在哈希环上分布的均匀性就会比原来的真实节点好,从而使得数据分布也更加均匀。
Redis的数据分布和一致性Hash的理念比较像,可以将redis的slot当作一个虚拟节点,虚拟节点的数量是固定的,由用户决定虚拟节点放在哪个node上,具体参考 中集群的设计。
总结
数据节点集群化,除了数据需要分片外,通常还需要备份保障高可用,备份总会产生一致性问题,可以参考 分布式系统之一:分布式事务和一致性
对几种方案的一致性的总结,引⽤了Google App Engine联合创始⼈赖安·巴⾥特(Ryan Barrett)在2009年Google I/O上的演讲Transaction Across DataCenter视频 中的⼀张图

参考资料
本文作者: Song 本文链接: https://www.jiangyuesong.me 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!