布隆过滤器(Bloom Filter)和布谷鸟过滤器(Cuckoo Filter)
布隆过滤器Bloom Filter
原理
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
其结构很简单,就是一个包含m位的位数组,初始值全部为0,示意如下:

为了表达这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到的范围中。对任意一个元素x,第i个哈希函数映射的位置就会被置为1(1≤i≤k)
简单点说,对于任意一个元素x,对其使用k个hash函数,得到hash值h1,h2..hk,将布隆过滤器中h1~hk对应的位置置为1
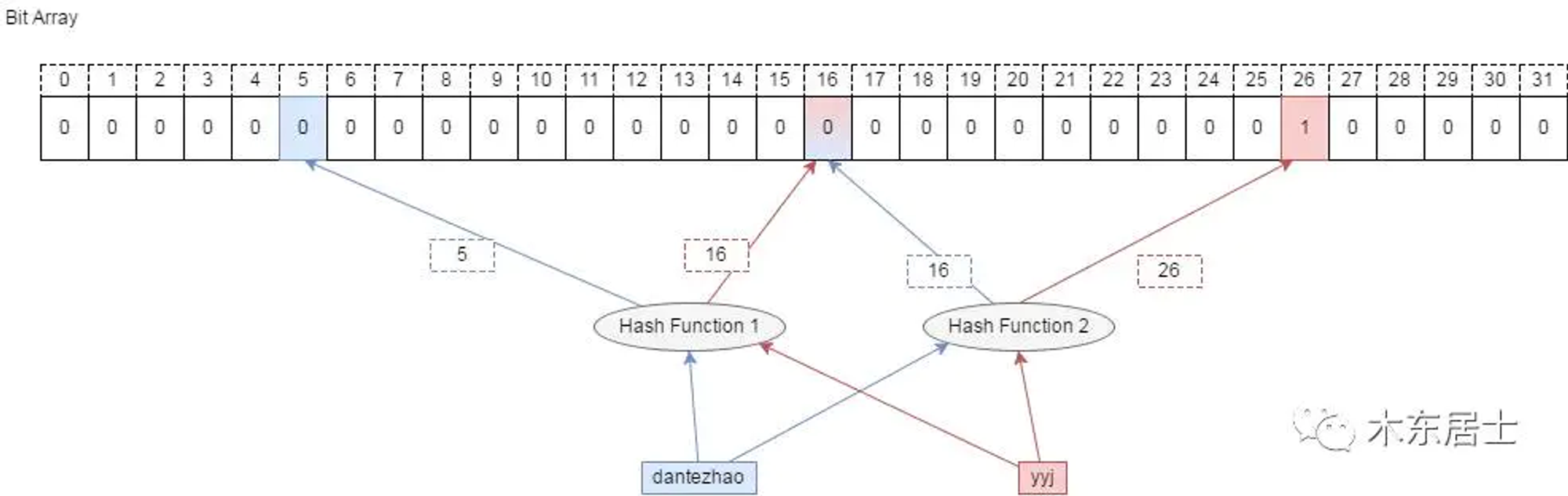
上图,yyj的hash值为16和26,只需要将数组的16和26位设置为1。
判断一个元素是否存在,同样计算k次hash值,判断对应位置是否全部为1即可
假阳性率False Positive
如果判断一个元素不存在,则一定不存在;如果判断存在,实际上不一定存在。
能提供“一定不存在”,但只能提供“可能存在”
因为,例如字符串s1的hash值是5、16,字符串s2的hash值是16和26,字符串s3的hash值是5和26;当s1和s2存在于布隆过滤器中时,s3即使不存在,也会被误认为存在。
具体的数学计算过程可以参考wiki百科的介绍中的过程,m代表bit数组的大小,k代表hash函数的个数,n代表bloom filter中元素的数量,最终假阳性率约为:
最佳hash函数的个数为
此时,可以得到最低的false positive为
反推内存
根据期望的假阳性率和数据量可以反推需要使用的内存:
在的情况下,粗略计算需要的内存
- 1亿数据457M
- 10亿数据5141M
- 100亿数据57131M
内存大小受数据量影响比较大,受p的值影响较小
n = ceil(m / (-k / log(1 - exp(log(p) / k)))) p = pow(1 - exp(-k / (m / n)), k) m = ceil((n * log(p)) / log(1 / pow(2, log(2)))); k = round((m / n) * log(2));
Counting Bloom Filter
bloom filter中数据是不能移除的,参考上方的例子。如果s1和s2都添加到bloom filter中,移除s2将会导致s1不存在。一种改进的方式,是每个位置不再是0-1bit位,而是存储一个数字(即多个bit位代替bloom的一个bit),每次插入该位置时,counter+1,删除数据时,counter-1。
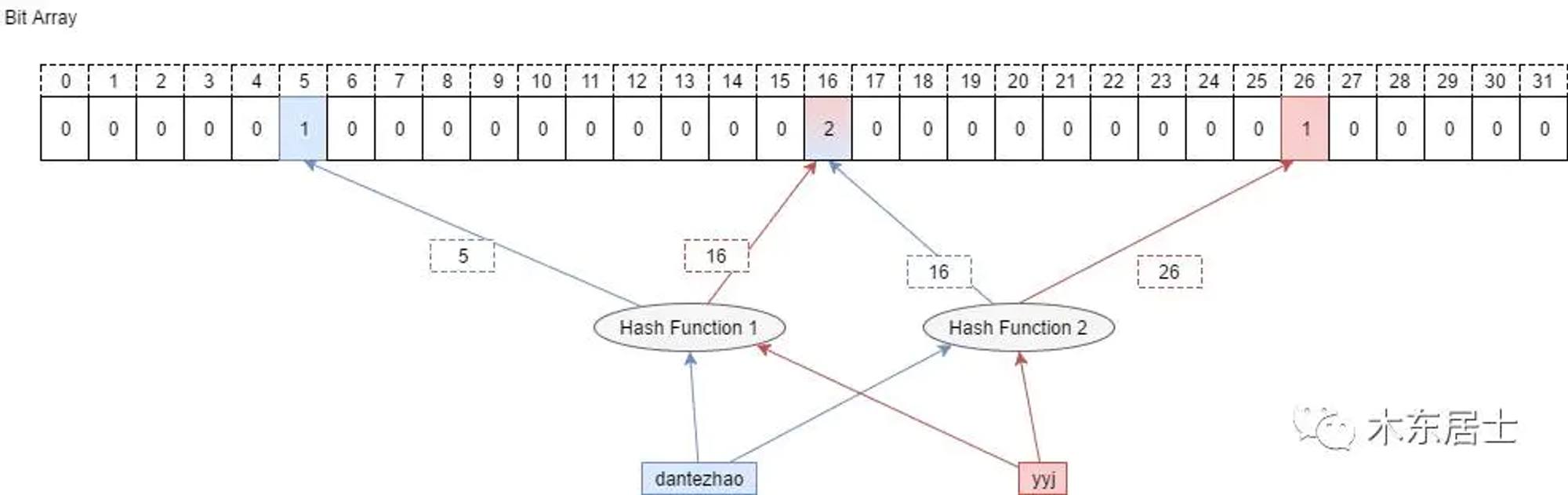
一般count设置4位就行,可以计数16次
布谷鸟过滤器Cuckoo Filter
布隆过滤器存在几个缺点:
- 空间效率低:初期无论使用多少内存,都要分配整个数组的,因为扩张数组大小,需要重新载入数据。
- CPU效率低:一个数据s的k次hash值在内存中分布的比较分散,不能很好的利用缓存
- 不支持删除和计数
最近有听说一个新的布谷鸟过滤器,为什么叫布谷鸟呢?来源于「鸠占鹊巢」,布谷鸟孵卵都是占用别人的窝,将别的鸟的蛋扔掉换成自己的,和布谷鸟过滤器很像。
布谷鸟哈希
基本思想是使用2个hash函数来处理碰撞,从而每个key都对应到2个位置。(这个2是可以扩增的)。其提出是期望通过解决hash碰撞,来提高hash table的空间利用率。
插入操作如下:
- 对key值hash,生成两个hash key值,hashk1和 hashk2, 如果对应的两个位置上有一个为空,那么直接把key插入即可。
- 否则,任选一个位置,把key值插入,把已经在那个位置的key值踢出来。
- 被踢出来的key值,需要重新插入,直到没有key被踢出为止。
以上存在一个问题,那就是可能会存在挤兑循环。比如两个不同的元素,hash 之后的两个位置正好相同,这时候它们一人一个位置没有问题。但是这时候来了第三个元素,它 hash 之后的位置也和它们一样,很明显,这时候会出现挤兑的循环。
即使不像上述那样产生循环,也可能产生一个比较大的挤兑链条,通常使用的时候,会设置一个阈值,当一次插入时剔除、插入执行的次数超过阈值,认为数组太拥挤了,需要扩容。
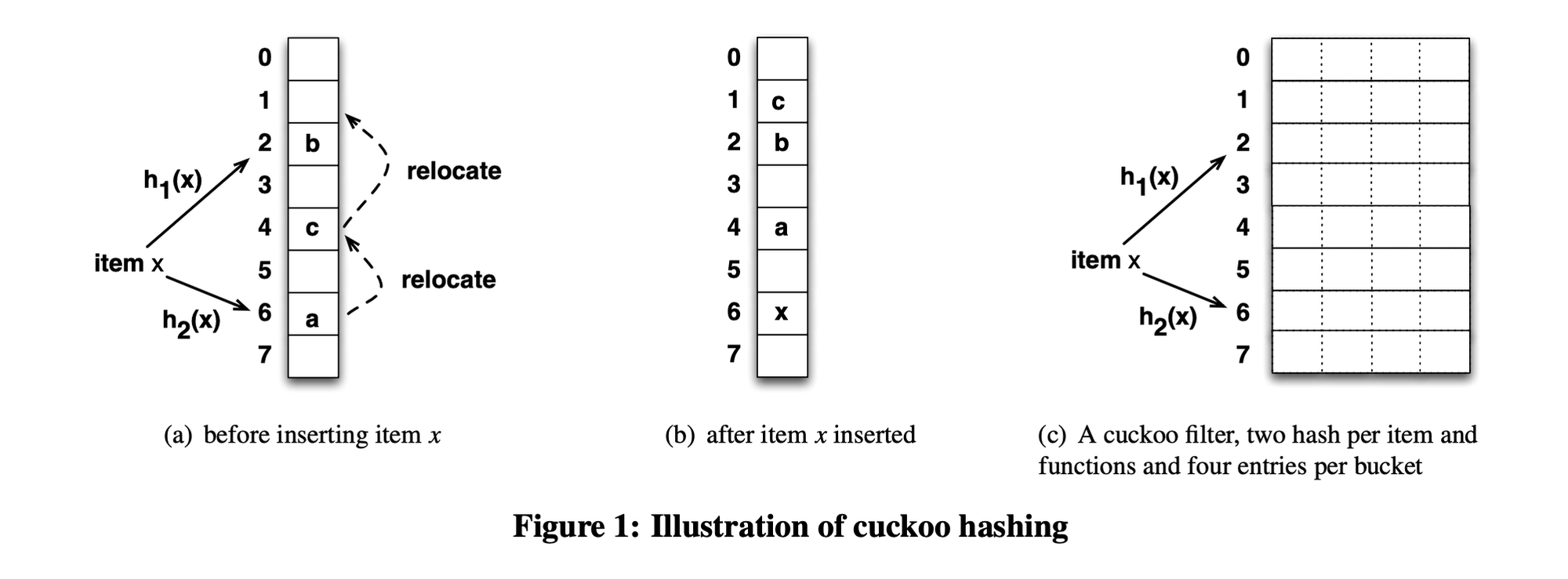
上图(a)中,假设插入元素x,其hash为2和6,两个位置都被占据了,于是踢出a,x占用6;a的hash是6和4,于是挪动a到4,踢出c;c的hash是1和4,挪动c到1,最终结果如(b)所示。
但是实际上,在不发生hash碰撞的时候,一维数组的空间利用率也只有50%,和其他hash函数差别不大,但是改成二维数组,如图(c)所示,可以提高空间利用率到90%。
在二维数组中,原先一个槽位扩展到4个,数据可以存储在其中任意一个位置,降低挤兑次数。
还有一种优化方案就是增加hash函数的数量。
过滤器
好了,以上介绍了cuckoo hash相关的,利用其理念,实现的filter。
首先,相对于上面的hash table,filter数组存储的不再是原始数据,而是指纹。与上述cuckoo hash的两个hash函数不同,布谷鸟过滤器巧妙的地方就在于设计了一个独特的 hash 函数,使得可以根据 p1 和 元素指纹 直接计算出 p2,而不需要完整的 x 元素。如下
fp = fingerprint(x) p1 = hash(x) p2 = p1 ^ hash(fp) // 异或
这样,也可以根据p2和指纹计算出p1
p1 = p2 ^ hash(fp)因为filter存储的是指纹,我们计算的两个hash值p1和p2必须和指纹相关联。
cuckoo filter设计上,也是采用了二维数组的slot,每个位置存储的是原始数据的指纹,对于数据S,计算指纹f,和hash值p1,然后根据两者计算p2,然后在p1 or p2所在位置,存储指纹
校验数据是否存在的时候,也是计算数据的指纹,然后去p1 or p2处查找。
两个问题:
- 为什么存储的是指纹
因为cuckoo filter实际上和hash table没有太大区别,还是找个位置,存储元素,但是存储元素本身太大了,所以改存储指纹
- 为什么p2要和指纹还有p1关联,而不是直接使用hash函数计算?
因为当发生两个hash结果都存储了元素的时候,需要把旧的踢走,旧的移动到新的位置,需要根据指纹和当前hash值,获得移动到哪里。
实践介绍
结合redis海量信息去重存储
之前的一个业务,主要是会采集海量的位置信息,包含设备MAC地址和经纬度、时间信息。关心的是设备的轨迹,所以如果设备长期呆在一个地方不移动,可以把N分钟之内的数据视为一个数据。
整个数据量大概一天在10亿~百亿,使用redis进行去重。几个核心的点:
- 使用redis的SETBIT命令
- redis一个key最大512M,在N分钟内数据量去重,会超过最大内存
- 根据设备MAC,不同MAC映射到不同的redis实例
- 对数据分桶,创建多个bloom filter,不同MAC映射到不同的filter内
- 采用Pipeline批量操作优化IO
曝光去重
在首页信息流推荐,需要过滤掉用户已经看过的内容。
- 每个用户,最多存储5000条已读记录
- 不能一次性初始化5000条的内存,太浪费,根据用户实际数据量,按照1000条的层级分配
参考链接
本文作者: Song 本文链接: https://www.jiangyuesong.me 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!